
Humans are intelligent enough to predict to a fair extent about what events and consequences will ensure an action. For example, when we strike a hammer on metal, our eyes shut off in anticipation of the noise even before the hammer strikes, or you can predict how a child will run by just watching a photo of him running.
Scientists at MIT have taken these traits and tried to merge them with artificial intelligence software. The results, as expected, are nothing short of astounding! The software takes a single image and uses its deep-learning algorithms to create a short video anticipating the action in the seconds that follow.
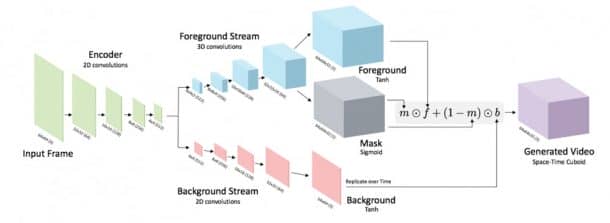
The algorithm created was trained using two million unlabelled videos, which amounted to almost a year long screen time. Divided into two two separate neural networks, it knows how to differentiate between the foreground and the background so that it can separate the object in the image from the background, enabling it to know what is moving and what is stationary.
This technology has been hailed as it can be refined and used to create smarter self-driving cars which will be able to anticipate any events on the road and be better prepared for the unexpected, along with a flurry of other applications such as improving security footage, animating still images and helping in compressing large video files. It can also be used to create a video of the future, which would entail using information in a certain video and then predict the future events with computer-generated vision frame by frame. The current software, for now, can produce up to 32 frames per second in one go.
The first author of the study, Carl Vondrick, says
“Building up a scene frame-by-frame is like a big game of ‘Telephone,’ which means that the message falls apart by the time you go around the whole room.By instead trying to predict all frames simultaneously, it’s as if you’re talking to everyone in the room at once.”
There are some improvements still needed, such as increasing the current time of 1.5 seconds. But creating an extended motion would require something very close to a human eye and intelligence, a tough ask indeed. The software also currently makes objects and humans much bigger than the reality, and the videos also lack resolution and details.
You can read more about the research online.
What are your thoughts on the video of the future? Comment below!

{kind=link}