
Meta has accomplished a remarkable feat as it steps forward toward another breakthrough. It has been reported by the company that a new speech-to-speech (S2ST) translation system has been developed that is capable of translating an oral language. As the research is in its initial stages of development, only one language, i.e., Hokkein, which is an oral language spoken in some parts of China, has been taken into consideration. Now, Hokkein, which is also one of the national languages of Taiwan, will be translated meticulously through this newly developed speech-to-speech translator.
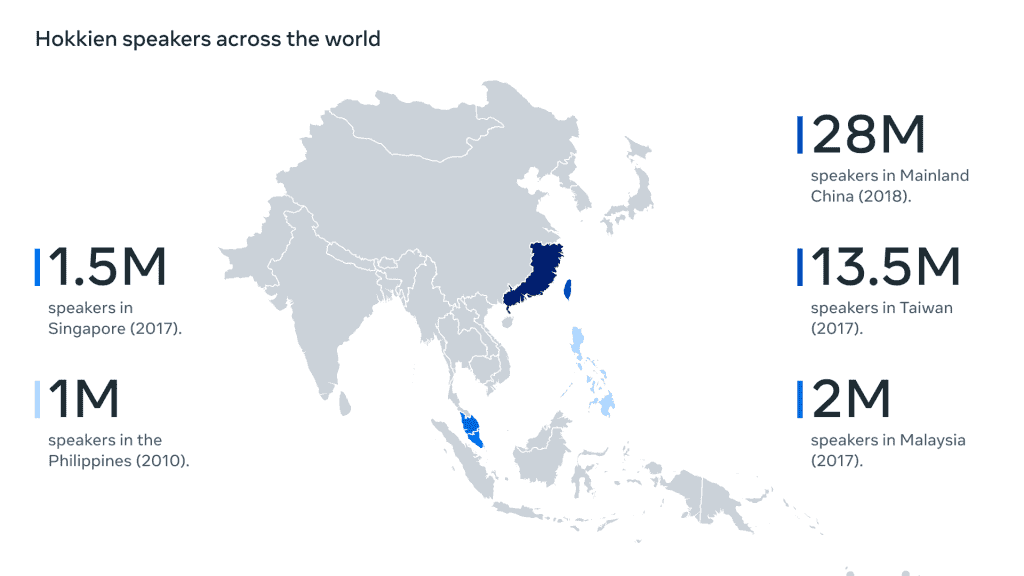
The research has been considered a breakthrough because, to date, there has been very little to no work done in the translation of oral languages, and the translation of Hokkein, which has been spoken by millions of people in the suburbs of China, is no less than a breakthrough. Coupled with this, around half of the world’s languages are spoken languages, and that amounts to about 7000 languages. Although the use of AI has been focused exclusively on the translation of written languages, this milestone will open new doors toward future development in this field.

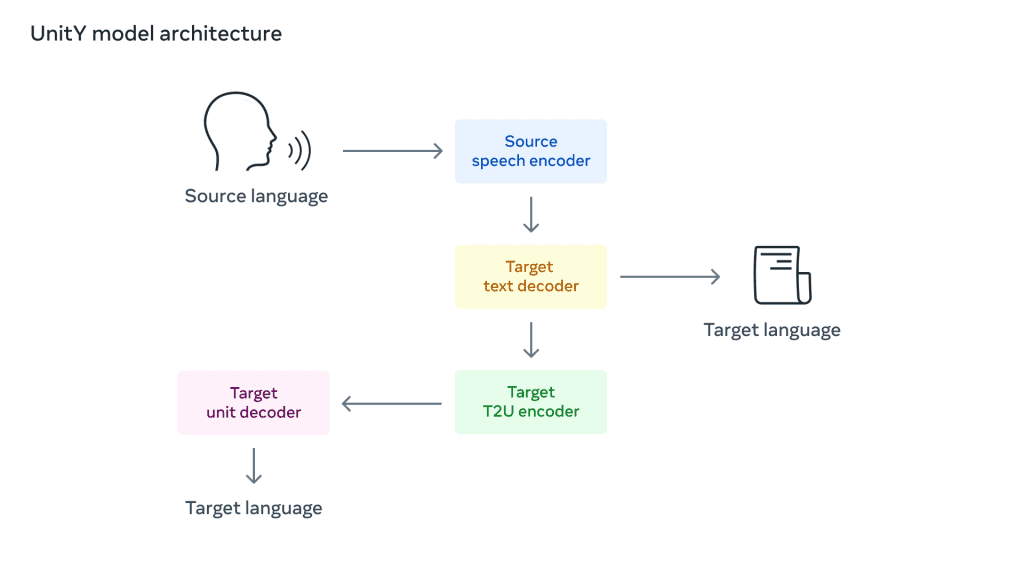
In addition to this, Meta wrote in a blog post, “We used speech-to-unit translation (S2UT) to translate input speech to a sequence of acoustic units directly in the path previously pioneered by Meta. Then, we generated waveforms from the units. In addition, UnitY was adopted for a two-pass decoding mechanism, where the first-pass decoder generates text in a related language (Mandarin) and the second-pass decoder creates units. ” Hence, this new speech-to-speech translation system has been supervised by Meta’s Universal Speech Translator (UST) project and is setting the stage for researchers to do work in this field in the future.
To that end, there are some challenges that are coming it’s way, and the company has to resolve them in order to ensure the efficiency of the system. This includes “data scarcity” because this is the first system launched recently and there is not enough data that would be fed into the translator for oral translations. Secondly, there are some words that seem different when spoken by people and are different in the order in which they are written.
However, the company said, “It will take much more work to provide everyone around the world with truly universal translation tools. But we believe the efforts described here are an important step forward. We’re open-sourcing not just our Hokkien translation models but also the evaluation datasets and research papers so that others can reproduce and build on our work.”

 translation system has been developed that is capable of translating an oral language. As the research is in its initial stages of development, only one language, i.e., Hokkein, which is […]&media=https://wonderfulengineering.com/wp-content/uploads/2022/10/ezgif-5-da323f5eb1.jpg){kind=link}