
In the future of robotics, a crucial element will be the ability of humans to instruct machines in real-time. However, the type of instruction needed for robots remains an open question. Google’s DeepMind has proposed a groundbreaking solution using a large language model called RT-2, similar to OpenAI’s ChatGPT. This model allows users to communicate with robots as effortlessly as chatting with ChatGPT.
RT-2, also known as “robotics transformer,” represents a vision-language-action model that enables robots to comprehend and execute actions based on human instructions. The key insight is to treat robot actions as a form of language, making them trainable just like ChatGPT is trained on text from the internet. The robot’s actions are encoded as coordinates in space, known as degrees of freedom, and integrated into the language and image tokens during training.
“The action space consists of 6-DoF [degree of freedom] positional and rotational displacement of the robot end-effector, as well as the level of extension of the robot gripper and a special discrete command for terminating the episode, which should be triggered by the policy to signal successful completion.”
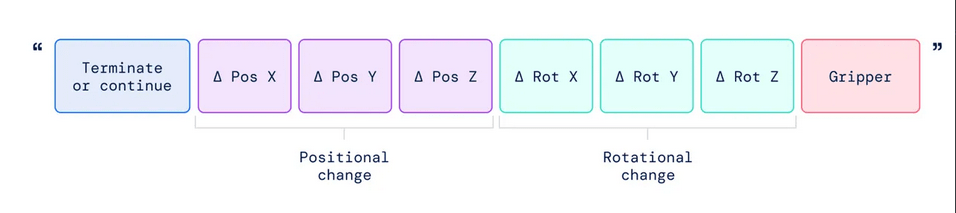
This approach is a significant milestone as it combines the physics of robots with language and image neural nets. RT-2 builds upon two previous Google efforts, PaLI-X and PaLM-E, which are vision-language models that relate data from text and images. PaLM-E goes a step further by generating commands to drive a robot based on language and image input. However, RT-2 surpasses PaLM-E by generating both the plan of action and the coordinates of movement in space.
RT-2 “is a significant advance,” said Sergey Levine, associate professor in the electrical engineering department at the University of California at Berkeley, in an e-mail correspondence with ZDNET. “Essentially RT-2 can be thought of as an end-to-end version of what PaLM-E + RT1 accomplish, in one model,” said Levine, who worked on the PaLM-E project. “This makes transfer of internet-scale knowledge to robots more direct, and may provide a more scalable class of approaches in the future.”
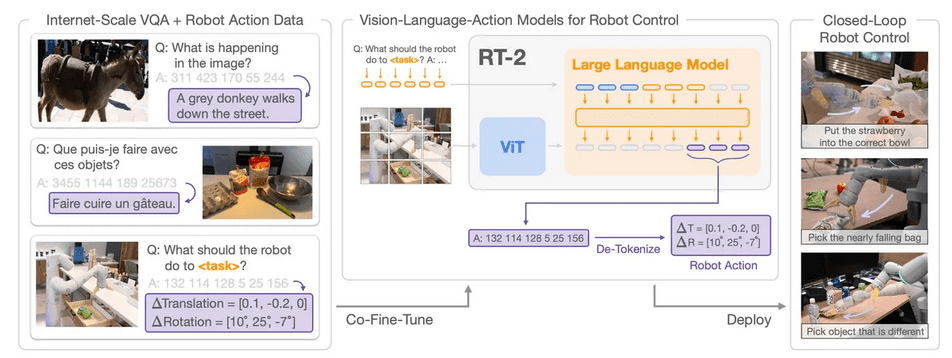
RT-2 is an improvement over its predecessor, RT-1, as it is based on larger language models with more neural weights, making it more proficient. After training RT-2, the authors conduct tests where the robot performs various tasks by following natural-language commands and images.
For example, when presented with a prompt, where the image shows a table with a bunch of cans and a candy bar:
Given Instruction: Pick the object that is different from all other objects
The robot will generate an action accompanied by coordinates to pick up the candy bar:
Prediction: Plan: pick rxbar chocolate. Action: 1 128 129 125 131 125 128 127
The three-digit numbers are keys to a code book of coordinate movements.

The robot demonstrates the ability to generalize to novel situations, showing competence in reasoning, symbol understanding, and human recognition.
A key aspect is that many elements of the tasks might be brand-new, never-before-seen objects. “RT-2 is able to generalize to a variety of real-world situations that require reasoning, symbol understanding, and human recognition,” they relate.
“We observe a number of emergent capabilities,” as a result. “The model is able to re-purpose pick and place skills learned from robot data to place objects near semantically indicated locations, such as specific numbers or icons, despite those cues not being present in the robot data. The model can also interpret relations between objects to determine which object to pick and where to place it, despite no such relations being provided in the robot demonstrations.”
When compared to RT-1 and other programs, RT-2 using either PaLI-X or PaLM-E achieves about 60% success in completing tasks involving previously unseen objects, while previous programs only achieve less than 50%.
There are also differences between PaLI-X, which is not developed specifically for robots, and PaLM-E, which is. “We also note that while the larger PaLI-X-based model results in better symbol understanding, reasoning, and person recognition performance on average, the smaller PaLM-E-based model has an edge on tasks that involve math reasoning.” The authors attribute that advantage to “the different pre-training mixture used in PaLM-E, which results in a model that is more capable at math calculation than the mostly visually pre-trained PaLI-X.”
The authors conclude that using vision-language-action programs can “put the field of robot learning in a strategic position to further improve with advancements in other fields,” so that the approach can benefit as language and image handling get better.
The authors emphasize that vision-language-action programs can lead to advancements in robot learning as language and image handling improves in other fields. However, there is a caveat: large language models are computationally intensive, which may hinder real-time responses from the robot.
“The computation cost of these models is high, and as these methods are applied to settings that demand high-frequency control, real-time inference may become a major bottleneck,” they write. “An exciting direction for future research is to explore quantization and distillation techniques that might enable such models to run at higher rates or on lower-cost hardware.”

{kind=link}