
Owing to CEO Mark Zuckerberg’s ‘one of the world’s fastest supercomputers,’ Meta’s new AI model can translate 200 different languages!
The company calls this program No Language Left Behind (NLLB) and it hopes to enable more than 25 billion translations across Meta’s apps each day.
The low resources languages like Egyptian Arabic, Balinese, Sardinian, Nigerian Fulfulde, Pangasinan, and Umbundu are spoken by a sizeable population but not as much on the internet itself.
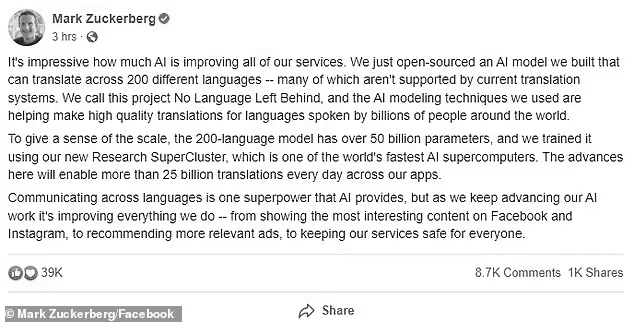
‘The AI modeling techniques we used are helping make high quality translations for languages spoken by billions of people around the world,’ Meta CEO Mark Zuckerberg said in a statement posted to Facebook.
The new model can translate 55 African languages with ‘high-quality results,’ the company states
‘To give a sense of the scale, the 200-language model has over 50 billion parameters, and we trained it using our new Research SuperCluster, which is one of the world’s fastest AI supercomputers.
‘The advances here will enable more than 25 billion translations every day across our apps.’
‘Communicating across languages is one superpower that AI provides, but as we keep advancing our AI work it’s improving everything we do — from showing the most interesting content on Facebook and Instagram, to recommending more relevant ads, to keeping our services safe for everyone.’
‘This means that this can impact billions of people by allowing them to communicate in their own native language,’ says Marta R. Costa-jussa, a research scientist at Meta AI, in a video announcing the effort.
‘This is going to change the way that people live their lives, the way they do business, the way that they are educated, No Language Left Behind really keeps that mission at the heart of what we do — is people,’ says Al Youngblood, a user researcher at Meta AI.

The company conducted exploratory interviews with native speakers of the low-resource languages to figure out the translation needs. Then it developed a computational model that’s trained on data obtained with unique and effective data mining techniques tailored for low-resource languages.
‘Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200,’ the team of researchers state in the abstract of the paper explaining the new AI model.
This will also help reduce digital inequality.
‘Given that the primary goal of NLLB is to reduce language inequities in a global context, more and more low-resource languages will be incorporated into the project (or others alike) in the long run,’ the researchers state.

 and it hopes to enable more than 25 billion translations across Meta’s apps each day. The low resources languages like Egyptian Arabic, Balinese, Sardinian, Nigerian […]&media=https://wonderfulengineering.com/wp-content/uploads/2022/07/imgonline-com-ua-resize-jlYk2PuyrbHD.jpg){kind=link}