
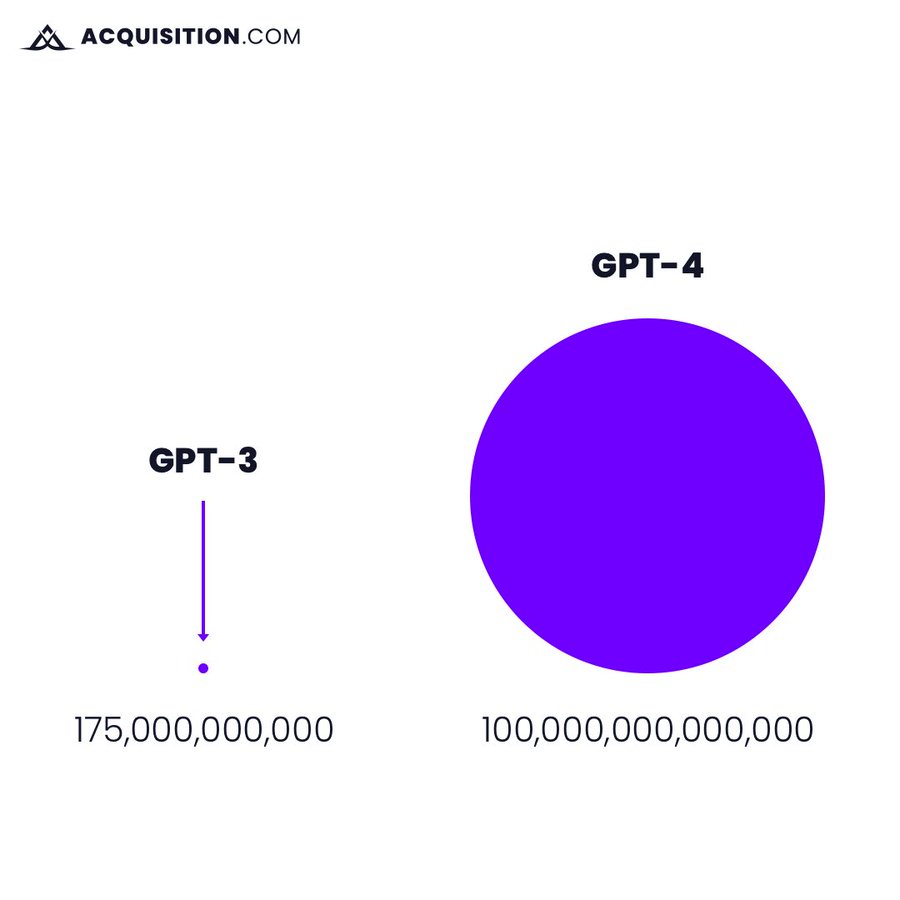
On Tuesday, OpenAI announced the latest version of its primary large language model, GPT-4, which the company claims displays “human-level performance” on various professional tests. The new model, ChatGPT-4, is larger than its predecessors, having been trained on more data and having more weights in its model file. As a result, it is more expensive to run.
Scaling up models is becoming increasingly popular among AI researchers, as evidenced by many recent advancements in the field. This approach involves running larger models on thousands of supercomputers in training processes that can cost tens of millions of dollars. GPT-4 is an example of this approach, which aims to achieve better results.
OpenAI trained ChatGPT-4 using Microsoft Azure, as Microsoft has invested billions in the startup. However, OpenAI did not reveal any information about the specific model size or hardware used in training, citing the competitive landscape.
Bing’s AI chatbot uses GPT-4, according to Microsoft. The latest version of GPT-4 offers a preview of new advancements that could begin filtering down to consumer products like chatbots in the coming weeks.
OpenAI has announced that their latest model, GPT-4, is expected to produce fewer factually incorrect answers and will be less likely to veer off-topic during conversations. In fact, the company claims that in many standardized tests, GPT-4 is expected to perform better than humans.
According to OpenAI, GPT-4 achieved impressive results in simulated exams, performing at the 90th percentile on a simulated bar exam, the 93rd percentile on an SAT reading exam, and the 89th percentile on the SAT Math exam.
However, OpenAI also acknowledges that the new model isn’t perfect yet and is less capable than humans in many scenarios. For instance, GPT-4 still suffers from hallucination, where it creates responses based on incomplete or inaccurate information. OpenAI says that the new model is also prone to insisting it is correct when it is actually wrong.
Despite these limitations, OpenAI suggests that GPT-4 is more reliable, creative, and can handle more nuanced instructions than its predecessor, GPT-3.5.
The new model will be available to paid ChatGPT subscribers and as part of an API that allows programmers to integrate AI into their apps. OpenAI plans to charge about 3 cents for about 750 words of prompts and 6 cents for about 750 words in response.

{kind=link}