
Microsoft’s latest AI innovation, VASA-1, blurs the line between reality and fiction by transforming static images of faces into lifelike animated clips of speech or song. The technology synchronizes lip movements with audio to create a convincing illusion of the subject speaking or singing. Although showcased with playful examples like Leonardo da Vinci’s Mona Lisa rapping, Microsoft acknowledges the potential for misuse, such as impersonation or fraud, and has refrained from releasing the tool publicly.
In a blog post, Microsoft researchers describe VASA as a ‘framework for generating lifelike talking faces of virtual characters’.
‘It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors,’ they say.
‘Our method is capable of not only producing precious lip-audio synchronisation, but also capturing a large spectrum of emotions and expressive facial nuances and natural head motions that contribute to the perception of realism and liveliness.’

VASA-1 operates by analyzing a still image of a face, whether real or fictional, and pairing it with audio to animate the face in real-time. Microsoft’s researchers tout VASA-1 as a framework for generating realistic talking faces, capable of conveying a range of emotions and nuances for lifelike interactions with digital avatars.
Jake Moore, a security specialist at ESET, said ‘seeing is most definitely not believing anymore’.
‘As this technology improves, it is a race against time to make sure everyone is fully aware of what is capable and that they should think twice before they accept correspondence as genuine,’ he told MailOnline.
‘However, like other related content generation techniques, it could still potentially be misused for impersonating humans,’ they add.
‘We are opposed to any behavior to create misleading or harmful contents of real persons, and are interested in applying our technique for advancing forgery detection.
‘Currently, the videos generated by this method still contain identifiable artifacts, and the numerical analysis shows that there’s still a gap to achieve the authenticity of real videos.’

Despite its promising applications, experts express concerns about the technology’s potential for deception and manipulation. With the ability to make individuals appear to say things they never said, VASA-1 could facilitate fraud and misinformation. Security specialists caution against blindly trusting visual content in an era where seeing no longer guarantees believing.
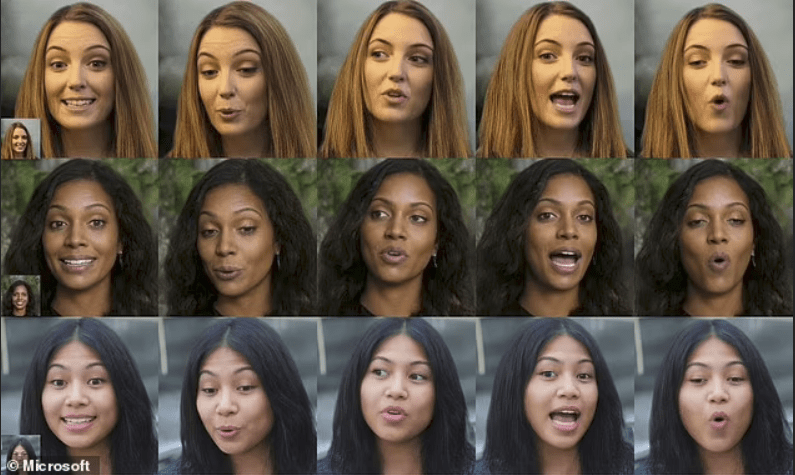
In response to these concerns, Microsoft emphasizes that VASA-1 is not intended for deceptive purposes and underscores its commitment to developing forgery detection methods. However, they acknowledge that the technology could still be exploited for nefarious ends. While current iterations of VASA-1 retain identifiable artifacts and fall short of replicating the authenticity of real videos, the rapid advancement of AI capabilities raises concerns about future implications.

Meanwhile, other AI developments, such as OpenAI’s Sora, which generates ultra-realistic video clips from text prompts, further compound these concerns. Experts warn of potential disruptions to industries like film production and the proliferation of deepfake videos, particularly in the political sphere.

The increasing convergence of reality and virtuality underscores the growing importance of ethical deliberations concerning AI technologies. Microsoft’s release of a research paper outlining VASA-1’s functionalities highlights the imperative for transparency and conscientious progress within the AI domain. While these technological strides offer vast opportunities, it is crucial to conscientiously address their ethical ramifications to minimize hazards and prevent exploitation.

{kind=link}