
Researchers have recently found a way to make reservoir computing a million times faster with significantly fewer computing resources and less data input needed.
In fact, researchers solved a complex computing problem in less than a second in one test of the next-generation reservoir computing.
“Using the current technology, the same problem requires a supercomputer to solve and still takes much longer,” said Daniel Gauthier, lead author of the study and professor of physics at The Ohio State University.

“We can perform very complex information processing tasks in a fraction of the time using much less computer resources compared to what reservoir computing can currently do,” Daniel added.
“And reservoir computing was already a significant improvement on what was previously possible.”
Reservoir computing is built on neural networks, which are machine learning systems trained to find patterns in large amounts of data and are modelled after how the brain works. So, for example, if a neural network is presented with 1000 photographs of a cat, it should recognize one every time it comes up.
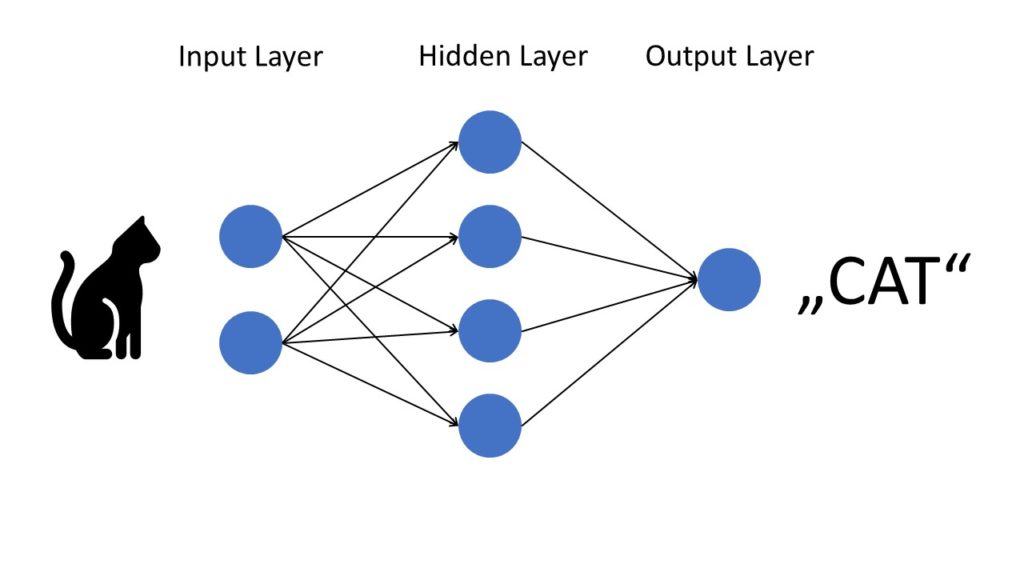
The reservoir computing details are highly sophisticated. First, scientists enter data into a ‘reservoir,’ where data sets are linked in many ways. The data is then retrieved from the reservoir, evaluated, and reintroduced into the learning process.
“The reservoir of artificial neurons is a black box,” Gauthier said, and scientists have not known exactly what goes on inside of it — they only know it works.
According to a recent study, removing the randomness from reservoir computers can improve their efficiency. A research was conducted to establish which components of a reservoir computer are crucial to its operation. Removing unnecessary bits shortens processing time.

The study found that a ‘warm up’ period, in which the neural network is fed training data to prepare it for the task at hand, is unnecessary. Here, the research team made substantial advancements.
“For our next-generation reservoir computing, there is almost no warming time needed,” says Gauthier.
“Currently, scientists have to put in 1,000 or 10,000 data points or more to warm it up. And that’s all data that is lost, that is not needed for the actual work. We only have to put in one or two or three data points.”
Depending on the data, the new approach proved to be between 33 and 163 times faster. However, when the goal was changed to maximize accuracy, the new model was a million times faster.

This super-efficient neural network is just getting started, and its developers intend to test it against much more challenging tasks in the future.
“What’s exciting is that this next generation of reservoir computing takes what was already very good and makes it significantly more efficient,” says Gauthier.
The research was published in Nature Communications.

{kind=link}