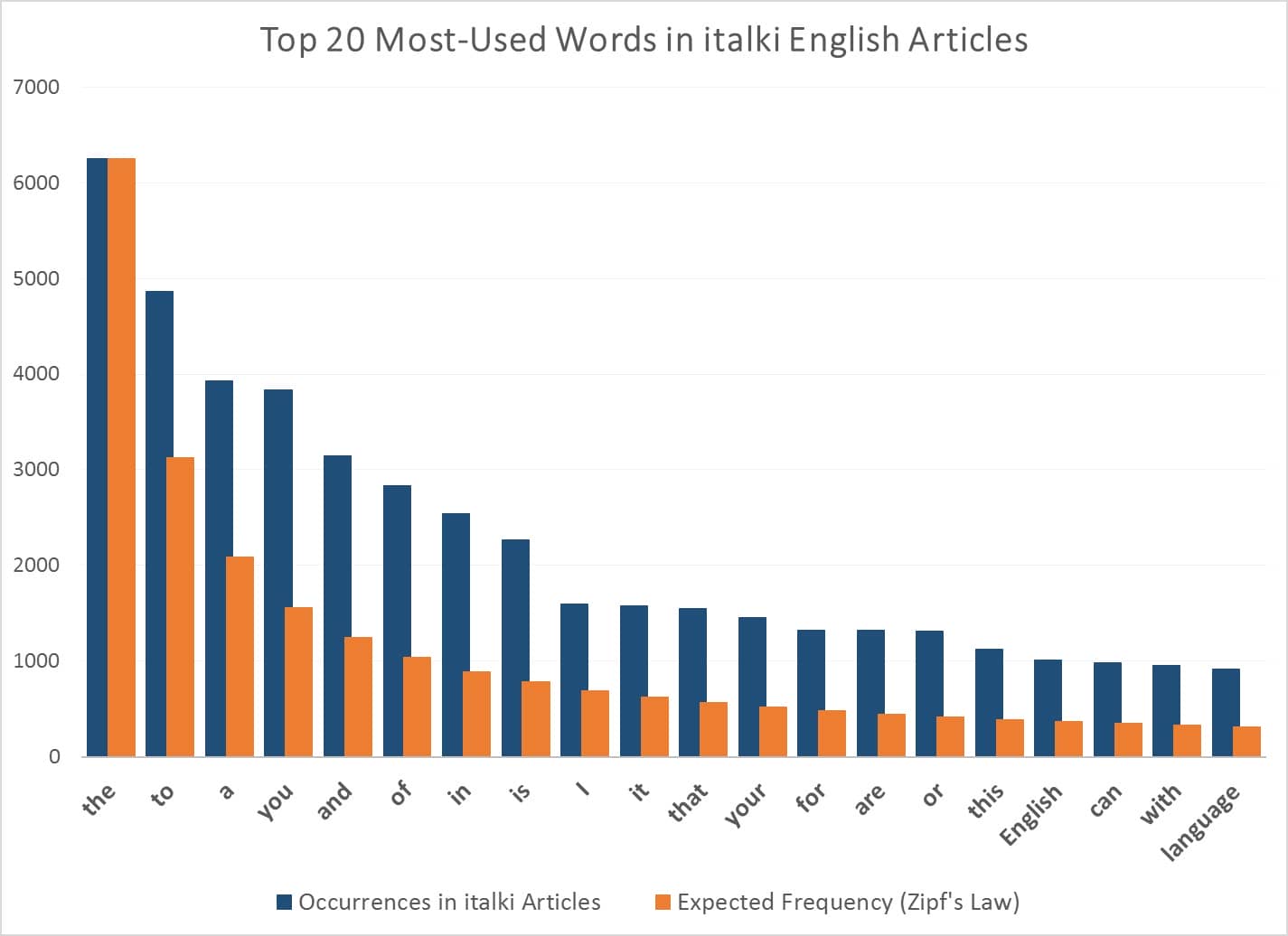
A lot of things must have boggled your mind, but the Zipf’s law is a step higher. The law states that if you pick any text, the frequency of any word is inversely proportional to its rank in the frequency table. So, the frequency of the highest occurring word will be twice as much as that of the second highest occurring word. Something like this:
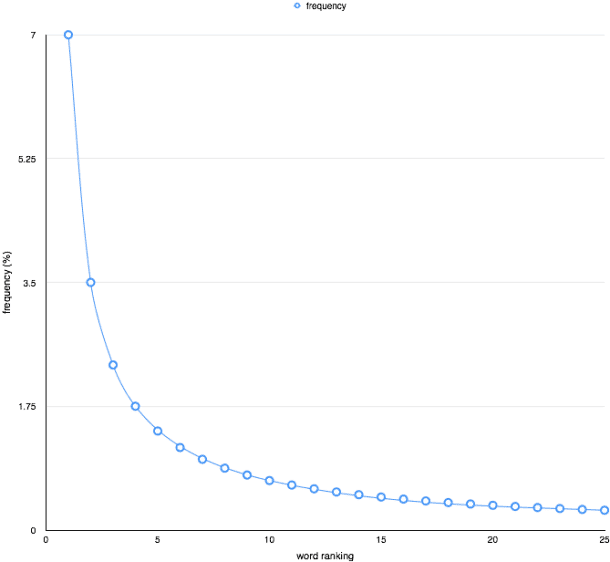
The same law forms a straight line when plotted on the logarithmic scale:
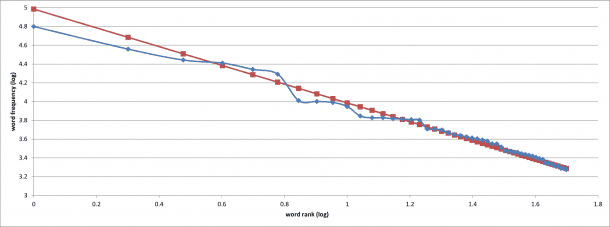
In any English text, the most frequently occurring words are, the, and, of, to, be, a, in, I, and that. There are a lot of other words in the text that do not occur quite as often. Linking all of these in the frequency table demonstrates the curve of Zipf’s law. According to a fascinating study at Oxford, these words make up 25% of all the text.
Of all that we speak, the word ‘the’ constitutes almost 6% and is the most frequent word. On the second place of the frequency scale, comes ‘of’ which is precisely 3% of everything that we say. The relation holds on, and the word which ranks third in the frequency table forms about 1.5% of our conversation.
Italki demonstrated the Zipf’s law using 140 of its English language learning articles. Collecting all 140 articles into a large document, they picked the 20 most occurring words to make predictions according to the Zipf’s law. The following graph shows how much different the reality and the predictions are
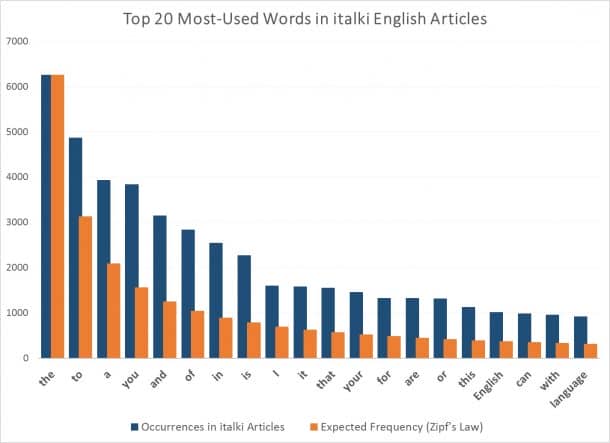
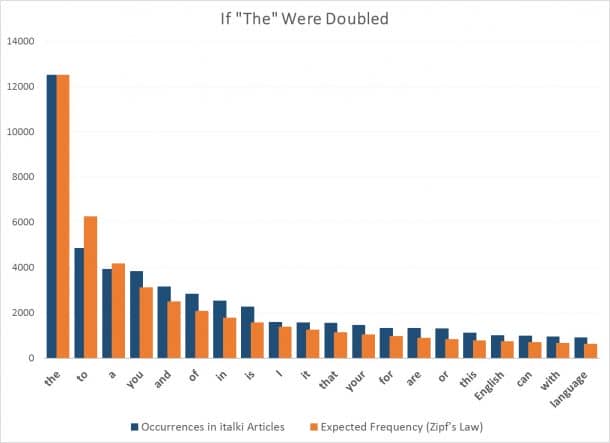
Mind boggling, right? You can use this very article and get a program to plot the Zipf’s curve for you, and you will get the same result.
The Zipf’s law not only predicts the occurrence of words in a text or a conversation but it also predicts other things like the rate at which the mega cities are growing on their population. The law applies to animals, nations, planets, mountains, and even on the sugar content of various cookies.
Would you like to plot the Zipf’s curve yourself? Comment below!

{kind=link}