
As traditional AI benchmarking methods struggle to keep pace with evolving generative AI models, developers are exploring unconventional evaluation techniques. One innovative approach gaining traction is the use of Minecraft, the widely popular sandbox game, to assess AI capabilities in a more engaging and relatable manner.
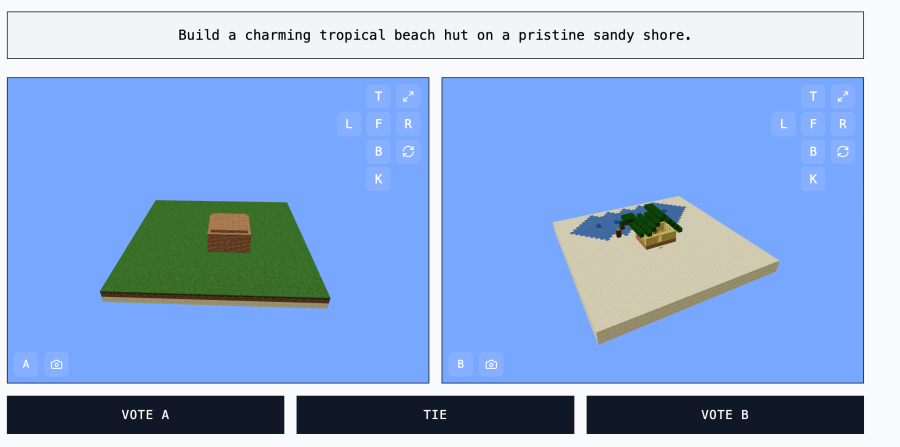
This initiative, known as Minecraft Benchmark (MC-Bench), provides a platform where AI models compete to generate Minecraft-based creations in response to prompts, allowing users to determine which model performs better. It was launched as a collaborative effort by a group of developers, including its founder, high school senior Adi Singh. The platform pits AI models against each other in creative building challenges, such as constructing a “Frosty the Snowman” or “a charming tropical beach hut on a pristine sandy shore.” Users vote on the best result before learning which AI model produced each build, ensuring unbiased assessment.
Singh highlights the accessibility of Minecraft as a benchmarking tool: “Minecraft allows people to see the progress [of AI development] much more easily. People are used to Minecraft, used to the look and the vibe.”
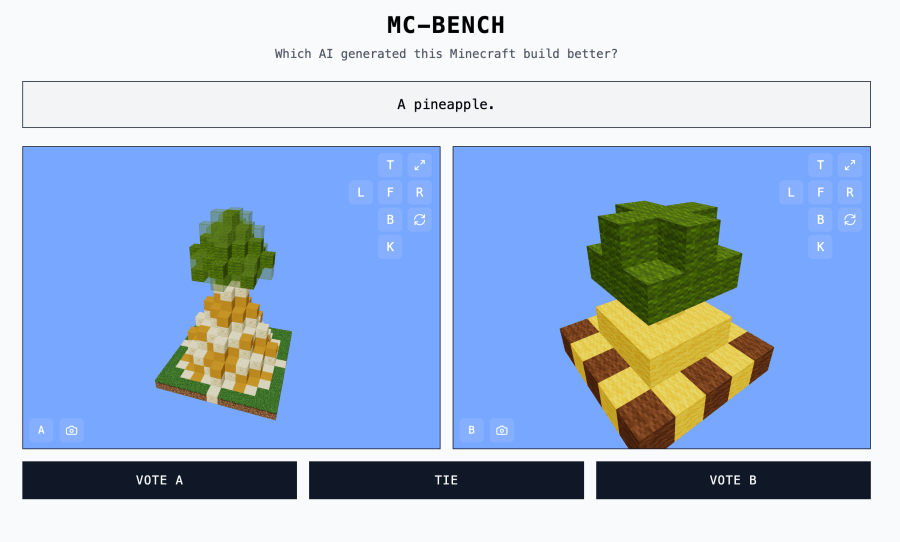
MC-Bench currently operates with contributions from eight volunteer developers. While tech giants like Anthropic, Google, OpenAI, and Alibaba provide resources to facilitate AI benchmarking on the platform, they are not directly affiliated with the project.
Singh envisions expanding MC-Bench beyond simple build tests to more sophisticated, long-term planning and goal-driven tasks. “Currently, we are just doing simple builds to reflect on how far we’ve come from the GPT-3 era, but [we] could see ourselves scaling to these longer-form plans and goal-oriented tasks,” he stated. “Games might just be a medium to test agentic reasoning that is safer than in real life and more controllable for testing purposes, making it more ideal in my eyes.”
AI benchmarking remains a difficult task due to inherent biases in traditional testing methods. Standardized evaluations often favor AI models due to their ability to process structured data efficiently. However, this doesn’t always translate to real-world intelligence. For instance, while OpenAI’s GPT-4 can score in the 88th percentile on the LSAT, it may struggle with basic tasks such as counting the number of Rs in “strawberry.”
Similarly, Anthropic’s Claude 3.7 Sonnet achieved 62.3% accuracy in software engineering benchmarks but performed poorly when playing Pokémon.
MC-Bench offers a different approach by requiring AI models to generate code that translates into Minecraft builds. This process allows for a more intuitive evaluation of AI’s reasoning and creative capabilities, rather than just its ability to process predefined datasets. The platform collects data on model performance, which could provide valuable insights for AI developers.

, provides a […]&media=https://wonderfulengineering.com/wp-content/uploads/2025/03/image-227.png){kind=link}